
Il semblerait que la division jeux de Sony étudie des solutions d'amélioration de l'image et des performances, à l'instar du DLSS et d'AMD Fidelity FXSR de Nvidia, alors que son dernier brevet explore des méthodes pour améliorer la qualité de l'image et combler les données manquantes via une combinaison d'apprentissage automatique. et la mise en œuvre informatisée.
Déposé en avril dernier et rendu public à la fin du mois dernier, le dernier brevet de Sony Interactive Entertainment détaille une solution potentielle pour offrir aux utilisateurs une meilleure qualité d'image.
Les images numériques peuvent contenir des régions de données d'image manquantes ou corrompues. Les régions manquantes ou corrompues sont appelées dans la technique des « trous ». Les trous sont normalement indésirables et des méthodes permettant de déduire quelles informations sont manquantes ou corrompues sont utilisées pour combler les trous. Combler les trous dans les images est également appelé complétion d’image ou inpainting.
Il existe divers procédés pour combler les trous dans les images. Les techniques d'inférence d'apprentissage automatique, qui s'appuient sur des processus entraînés, peuvent combler les trous dans les images avec des résultats de haute qualité. Cependant, les techniques d’apprentissage automatique sont gourmandes en performances, nécessitant un matériel informatique puissant et beaucoup de temps.
Des trous dans les images surviennent dans les systèmes de rendu basés sur des images. Par exemple, lorsqu'il existe deux images ou plus représentant des perspectives du même environnement, il peut n'y avoir aucune donnée d'image correspondant à une perspective intermédiaire qu'un utilisateur souhaiterait voir. Alternativement, certaines données d'image peuvent manquer dans l'une des perspectives. Des processus d'apprentissage automatique peuvent être utilisés pour déduire la perspective intermédiaire et pour déduire les données d'image manquantes. L’exécution de processus d’apprentissage automatique pour obtenir les données manquantes est coûteuse en termes de calcul et prend du temps.
Un exemple d'un système de rendu basé sur une image est un dispositif de réalité virtuelle affichant un environnement de réalité virtuelle. Un utilisateur portant un casque de réalité virtuelle se voit présenter, par deux moniteurs dans le casque, une représentation d'une scène tridimensionnelle. Lorsque l'utilisateur bouge la tête, une nouvelle scène est générée et affichée en fonction de la nouvelle position et orientation du casque. De cette façon, un utilisateur peut regarder autour d’un objet dans la scène. Les zones de la scène initiale qui deviennent visibles dans la nouvelle scène en raison du mouvement sont décrites comme étant auparavant « occluses ». Les scènes affichées peuvent être générées par du matériel informatique dans un ordinateur personnel ou une console connecté au casque, ou par un service de rendu basé sur le cloud distant du casque. La vitesse à laquelle les données d'image sont fournies au casque est limitée par la bande passante de la connexion entre le casque et l'ordinateur, la console ou le système de rendu basé sur le cloud. Par conséquent, parfois, toutes les données nécessaires à un moment donné pour construire et afficher entièrement une scène ne sont pas disponibles en raison de limitations ou d'interruptions de bande passante. Les trous dans les données d'image composant la scène sont un résultat indésirable et ont un impact négatif important sur l'immersion ressentie par l'utilisateur.
Il poursuit en indiquant qu'un avantage serait de réduire la charge sur un processeur dudit matériel.
Cela permet avantageusement de combler le trou de manière rapide et efficace, tout en augmentant la probabilité d'obtenir un résultat de haute qualité. Les pixels proches ayant des identifiants de matériau différents de ceux du pixel du trou sont plus susceptibles d'avoir un aspect différent des données de pixels manquantes, que ceux dont les identifiants de matériau correspondent. Par conséquent, l'utilisation de pixels avec les mêmes identifiants de matériau réduit avantageusement la charge de calcul sur un processeur, tout en obtenant de manière plus précise un pixel rempli de manière appropriée. La détermination de la moyenne peut inclure des valeurs de pondération des pixels environnants à moyenner.
Cela permet à certains pixels environnants de contribuer davantage à la moyenne que d'autres, augmentant ainsi avantageusement la polyvalence du processus de remplissage en fonction de l'image traitée. Le second processus de remplissage peut comprendre un processus d'inférence d'apprentissage automatique.
Les processus d'inférence d'apprentissage automatique fournissent des résultats de remplissage d'images de haute qualité. En fournissant un processus d'inférence d'apprentissage automatique en tant que deuxième processus de remplissage, on obtient avantageusement un équilibre amélioré entre la vitesse et la qualité du traitement d'image.
Certaines illustrations sont fournies pour décrire le déroulement du processus, ainsi qu'une présentation de quelques images avant et après.
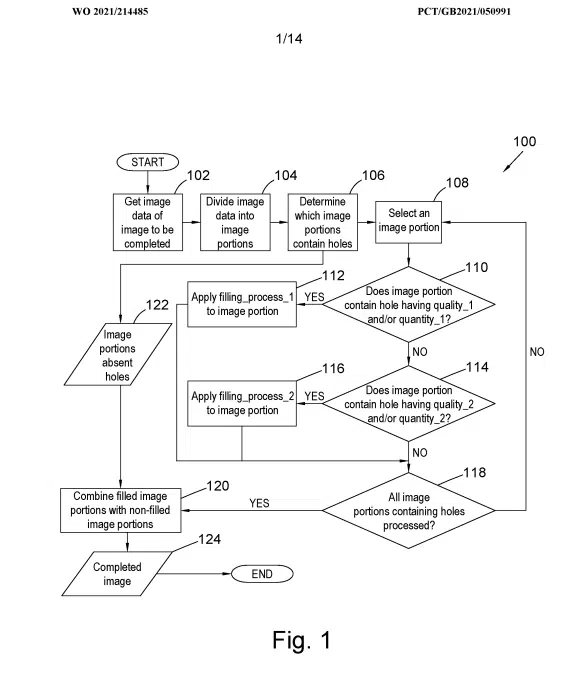

Cela va sans dire, étant donné qu’il s’agit d’un brevet, cela ne signifie pas nécessairement que nous verrons un jour cela se produire. Cependant, la société n'est pas étrangère à la technologie basée sur l'IA puisque le dernier-né de la gamme de téléviseurs Bravia, Bravia XR, prend en charge ce que l'on appelle « l'intelligence cognitive ». L'explication :
La façon dont nous percevons le monde repose sur les informations provenant à la fois de nos yeux et de nos oreilles vers notre cerveau. L’IA conventionnelle ne peut détecter et analyser des éléments tels que la couleur, le contraste et les détails qu’individuellement. Cognitive Processor XR peut analyser de manière croisée chaque élément à la fois, tout comme le fait notre cerveau.
Pour créer cette sensation de plus proche de la réalité, le Cognitive Processor XR divise l'écran en centaines de zones et reconnaît les objets individuels dans ces zones mieux que jamais. De plus, ils peuvent analyser de manière croisée quelques centaines de milliers d’éléments différents qui composent une image en une seconde, de la même manière que fonctionne notre cerveau.
À quoi ressemble l’intelligence cognitive :

Bien sûr, cela concerne leur télévision. Cependant, avec le soutien croissant du DLSS et d'AMD Fidelity FXSR, nous ne pensons pas qu'il soit exagéré que Sony développe ses propres solutions. Je suppose que nous devrons simplement attendre et voir ce que l’avenir nous réserve !